Paper: arXiv:2103.09474
Code: github.com/keonlee9420/STYLER
Authors: Keon Lee, Kyumin Park, Daeyoung Kim.
Abstract: Previous works on neural text-to-speech (TTS) have been addressed on limited speed in training and inference time, robustness for difficult synthesis conditions, expressiveness, and controllability. Although several approaches resolve some limitations, there has been no attempt to solve all weaknesses at once. In this paper, we propose STYLER, an expressive and controllable TTS framework with high-speed and robust synthesis. Our novel audio-text aligning method called Mel Calibrator and excluding autoregressive decoding enable rapid training and inference and robust synthesis on unseen data. Also, disentangled style factor modeling under supervision enlarges the controllability in synthesizing process leading to expressive TTS. On top of it, a novel noise modeling pipeline using domain adversarial training and Residual Decoding empowers noise-robust style transfer, decomposing the noise without any additional label. Various experiments demonstrate that STYLER is more effective in speed and robustness than expressive TTS with autoregressive decoding and more expressive and controllable than reading style non-autoregressive TTS. Synthesis samples and experiment results are provided via our demo page, and code is available publicly.
Style Factor Modeling
Try various style factor combinations. The model output (middle) is synthesized speech from single noisy audio (left) with given text. The orange line represents pitch contour, and the purple line represents energy. 'T', 'D', 'P', 'E', 'S', and 'N' refer to the text, duration, pitch, energy, speaker, and noise encoding. A selected combination of these encodings is fed into the model. Note that the clean audio (right) is shown for the comparison, and it is not given to the model during inference. SNR stands for signal-to-noise ratio, where a ratio higher than 1:1 (greater than 0 dB) indicates more signal than noise.
| Noisy Audio (Ground-truth) | STYLER | Clean Audio (Ground-truth) | |
|---|---|---|---|
| 1: Female speaker with SNR 25 (p233_045), "All businesses continue to trade." | |||
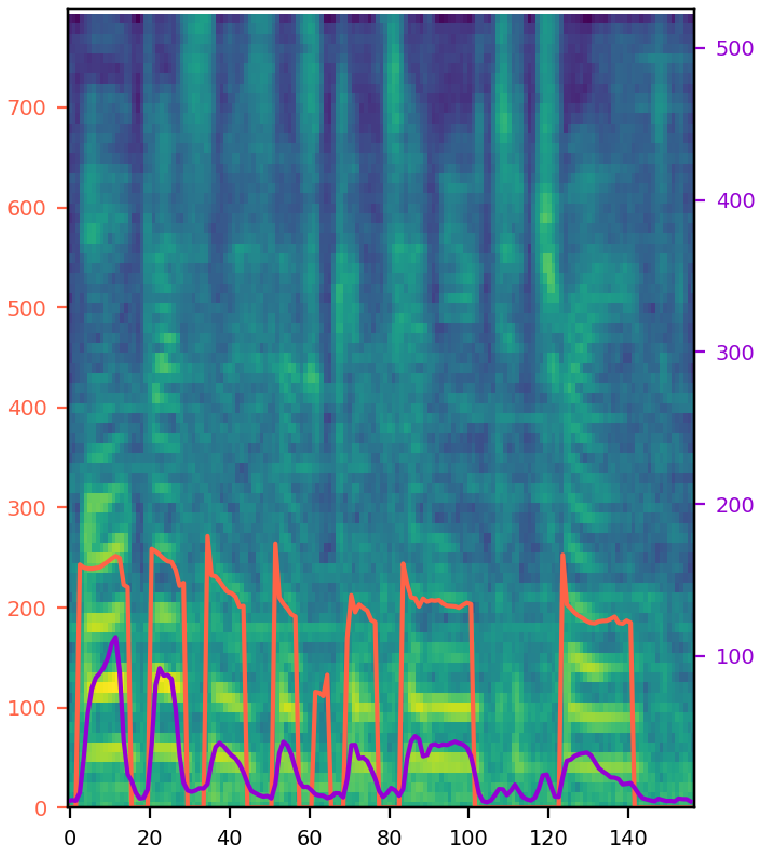 |
 |
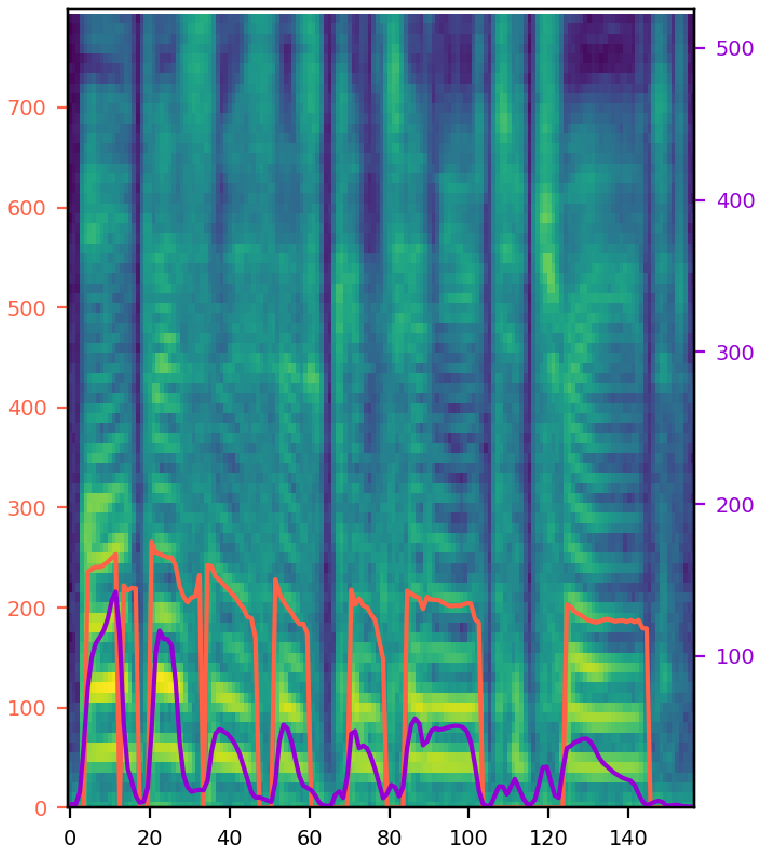 |
Combination: |
| 2: Male speaker with SNR 6 (p311_094), "The party has never fully recovered." | |||
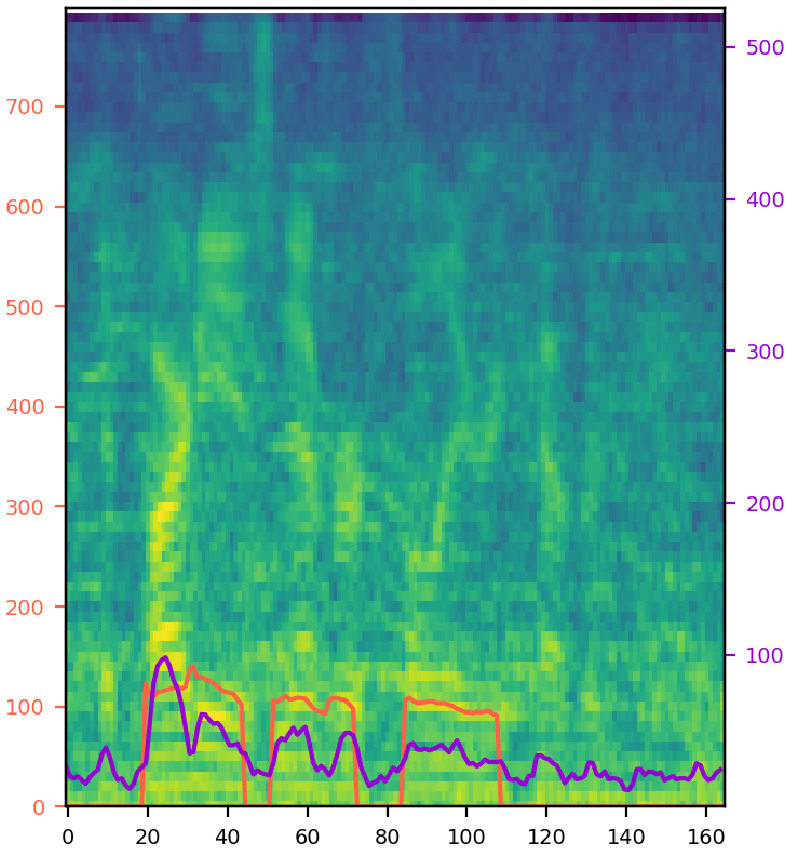 |
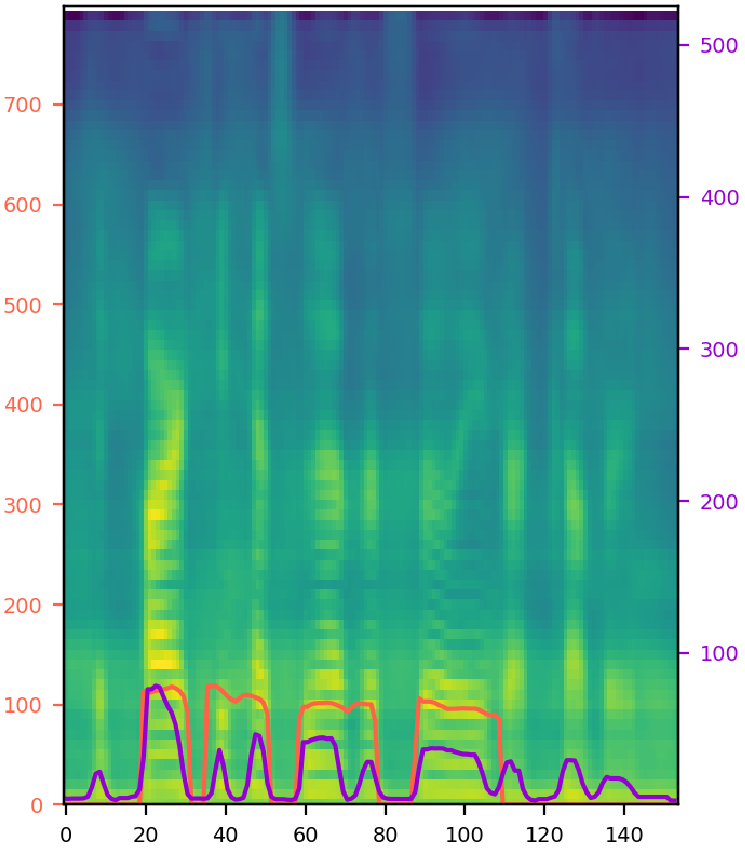 |
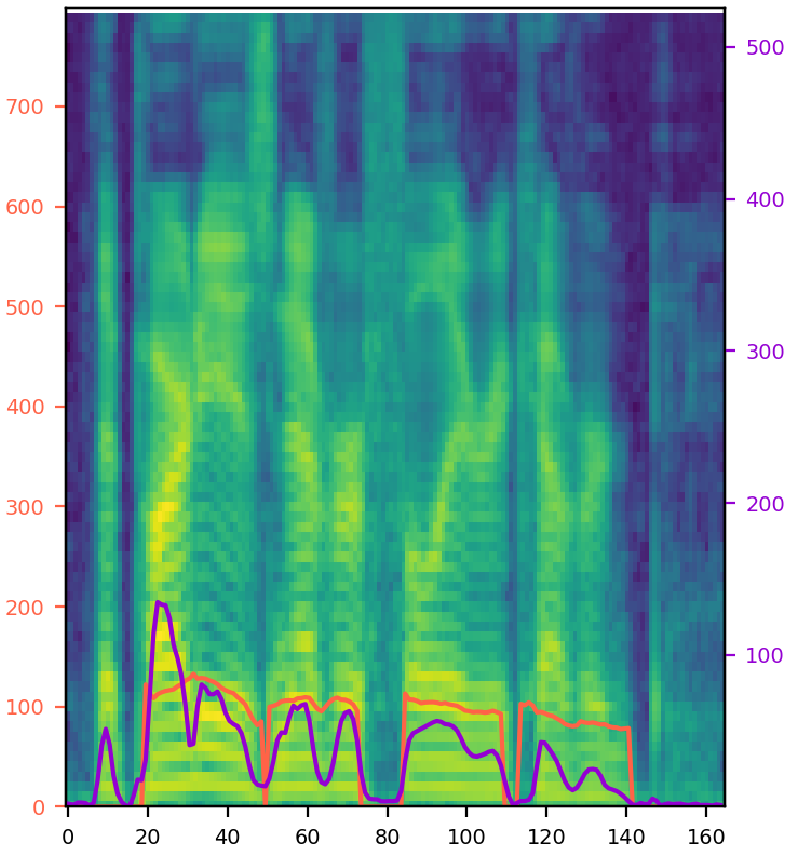 |
Combination: |
Style Factor Control
By style factor modeling, STYLER achieved controllability of style factors from different sources (input variants). In other words, input audio can vary for each of the style factors. Here, we demonstrate model controllability on 'T', 'D', 'P', 'E', and 'S' from two different audio of different speakers. In each dropbox, "1" refers to "Reference Audio 1" and "2" refers to "Reference Audio 2", and the corresponding style of selected reference audio is reflected on the output of STYLER. All plots are left-aligned for easy comparison.
| Reference Audio 1 (Ground-truth) | STYLER | Reference Audio 2 (Ground-truth) | |
|---|---|---|---|
| Reference Audio 1: Unseen Female (p323_229), "That period was a struggle."
Reference Audio 2: Seen Male (p259_284), "It makes no difference to their friendship." |
|||
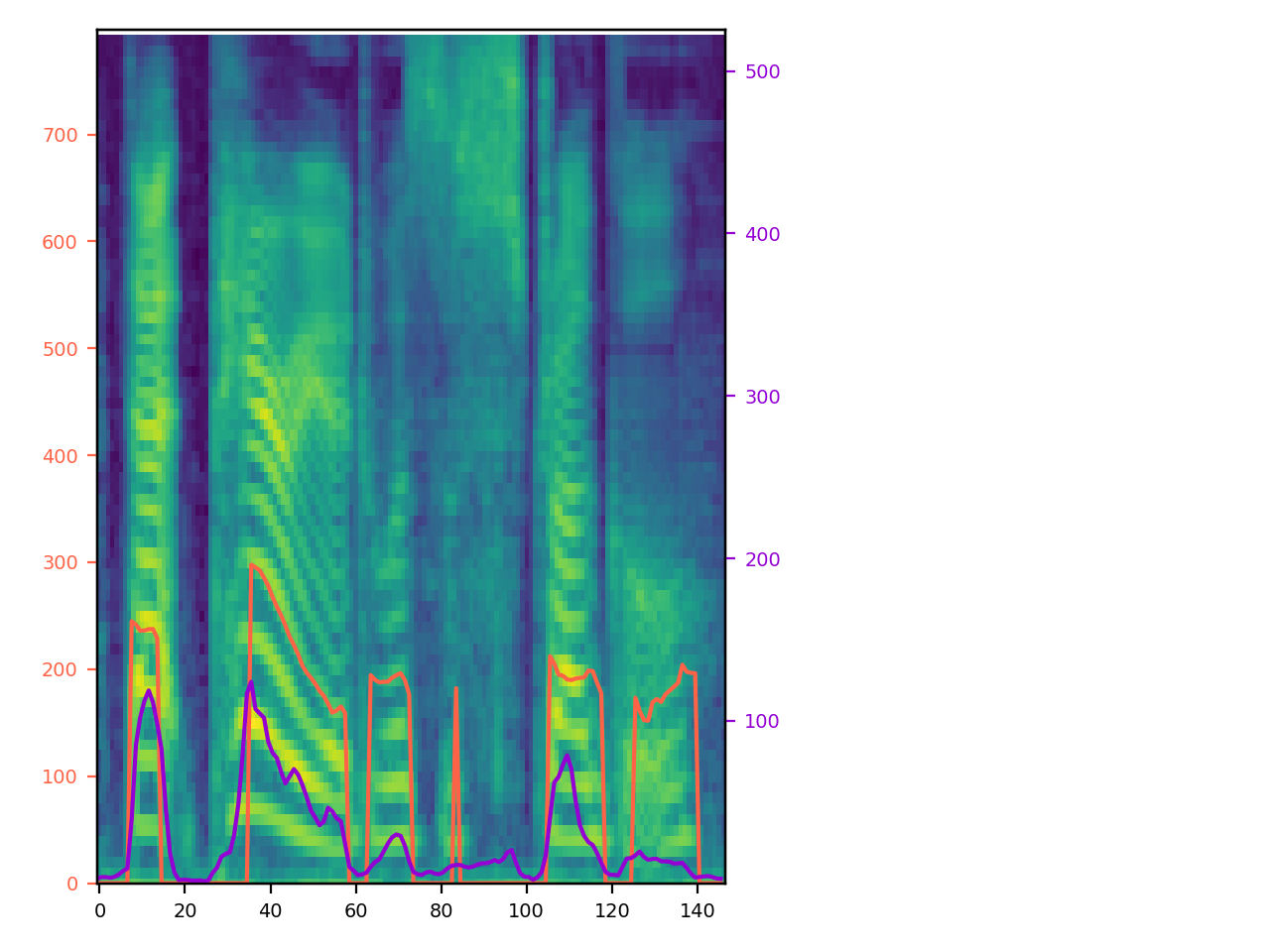 |
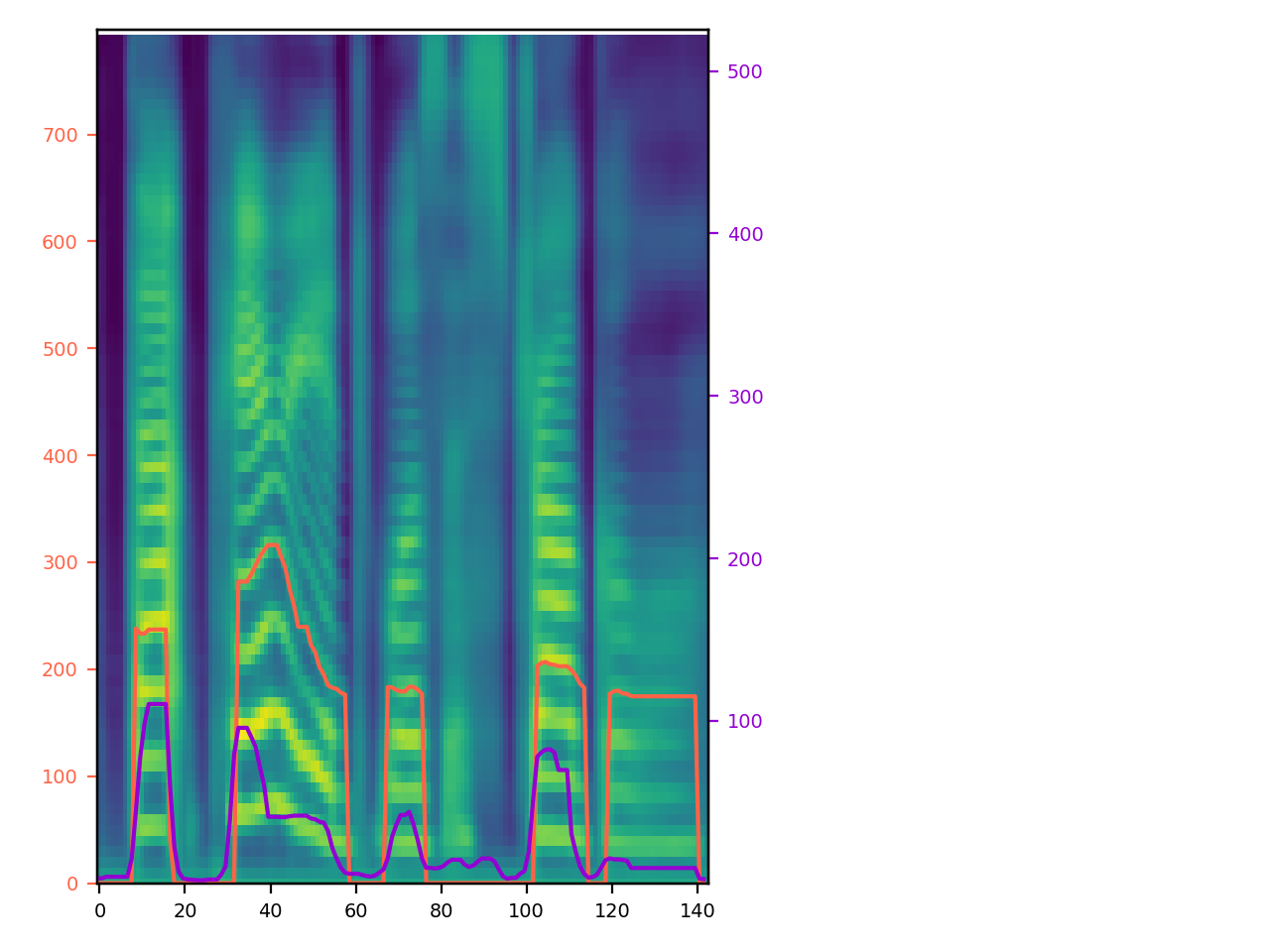 |
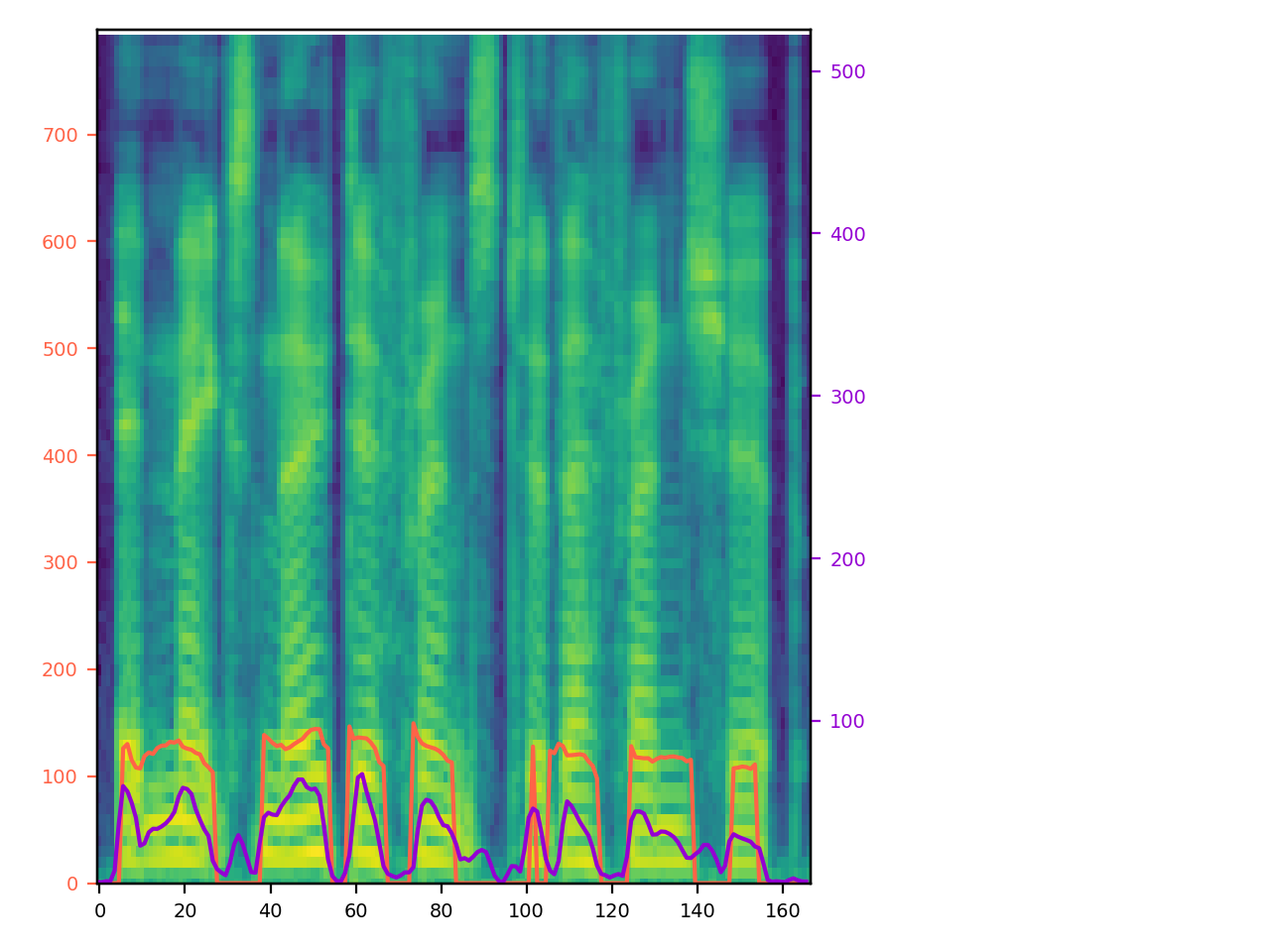 |
T: D: P: E: S: |
Style Transfer
In style transfer tasks, only clean audio is provided for each model, and the noise encoding is ignored in STYLER. For the parallel transfer, the audio content is the same with the input text. For the non-parallel transfer, the audio content is not matched with the input text.
Parallel samples from seen speaker.
| Input Audio (Ground-truth) | STYLER | FastSpeech2 | Mellotron |
|---|---|---|---|
| 1: p234_024, "This is a very common type of bow, one showing mainly red and yellow, with little or no green or blue." | |||
| 2: p248_130, "I had relied on him." | |||
| 3: p226_021, "The difference in the rainbow depends considerably upon the size of the drops, and the width of the colored band increases as the size of the drops increases." | |||
| 4: p247_234, "Murray financial has fallen at the first hurdle." | |||
| 5: p263_157, "Drugs are used a lot at the fishing, not just cannabis." | |||
Parallel samples from unseen speaker.
| Input Audio (Ground-truth) | STYLER | FastSpeech2 | Mellotron |
|---|---|---|---|
| 1: p239_148, "People have been placed in a state of alarm." | |||
| 2: p239_189, "Millions of british jobs depend on europe." | |||
| 3: p285_085, "Yesterday, he continued to keep a low profile." | |||
| 4: p285_255, "It will now relate to all public bodies in scotland." | |||
| 5: p285_364, "The final decision was between scotland and the republic of ireland." | |||
Non-parallel samples from seen speaker.
| Input Audio (Ground-truth) | STYLER | FastSpeech2 | Mellotron |
|---|---|---|---|
| 1: p234_024, "This is a very common type of bow, one showing mainly red and yellow, with little or no green or blue." (audio content), "Murray financial has fallen at the first hurdle." (target text) | |||
| 2: p248_130, "I had relied on him." (audio content), "Drugs are used a lot at the fishing, not just cannabis." (target text) | |||
| 3: p226_021, "The difference in the rainbow depends considerably upon the size of the drops, and the width of the colored band increases as the size of the drops increases." (audio content), "She can scoop these things into three red bags, and we will go meet her wednesday at the train station." (target text) | |||
| 4: p247_234, "Murray financial has fallen at the first hurdle." (audio content), "We also need a small plastic snake and a big toy frog for the kids." (target text) | |||
| 5: p263_157, "Drugs are used a lot at the fishing, not just cannabis." (audio content), "Murray financial has fallen at the first hurdle." (target text) | |||
Non-parallel samples from unseen speaker.
| Input Audio (Ground-truth) | STYLER | FastSpeech2 | Mellotron |
|---|---|---|---|
| 1: p323_229, "That period was a struggle." (audio content), "Finding suitable replacements would not be easy." (target text) | |||
| 2: p323_337, "He wasn't really doing anything, so he wanted out." (audio content), "People have been placed in a state of alarm." (target text) | |||
| 3: p279_258, "Blair is very positive at european councils." (audio content), "The guidelines are expected to be finalised before next spring." (target text) | |||
| 4: p279_389, "It will take place in july." (audio content), "Millions of british jobs depend on europe." (target text) | |||
| 5: p323_389, "I did not concentrate on my performance." (audio content), "It will now relate to all public bodies in scotland." (target text) | |||
Robustness
Repeated and Ignored Words
| STYLER | Mellotron |
|---|---|
| 1: p323_229, "That period was a struggle." | |
| 2: p248_130, "Had had been had had had not had but had had and had." | |
Style Transfer from Noisy Reference Audio
| Noisy Audio (Ground-truth) | STYLER (Noisy Decoding) | STYLER (Clean Decoding) | Mellotron |
|---|---|---|---|
| 1: Male seen speaker with SNR 23 (p237_274), "One mp said he feared the job losses were only the beginning." (audio content), "The difference in the rainbow depends considerably upon the size of the drops, and the width of the colored band increases as the size of the drops increases." (target text) | |||
| 2: Female seen speaker with SNR 23 (p297_004), "We also need a small plastic snake and a big toy frog for the kids." (audio content), "The next eight weeks are critical to us." (target text) | |||